



By Ernesto Spinak

Image: Freepik.
Publication of academic research results in open access is becoming more frequent and it is estimated that millions of documents are currently available online. For this reason, it is important to have efficient tools to find the free versions of the articles that we need (without paying for subscriptions or buying individual articles and using legal methods). As the need creates the offer, in the last two or three years, free applications have emerged to meet the requirements of academics, librarians, researchers, and students in general. What does the market offers nowadays?
This is where my favorite nerd, Aaron Tay – a librarian at the Singapore Management Library comes in, who recently wrote some notes1,2 on his blog, analyzing various plugins for browsers and the aggregator services that allow finding almost instantaneously complete texts in open access.
The following table shows the different services analyzed by Aaron Tay in several posts (the links are listed at the end of the post) with some comments and ratings of mine (which I consider myself a bit old to be a nerd!) Below in this post we will show examples of the two plugins that seem to us the most efficient ones – that is: they are the ones I use – but it should be a good exercise to do the tests yourself.
|
This service created by the Bielefeld University Library in Germany is probably one of the largest and most advanced aggregators in the world, surpassing in November 2016 the 100 million documents. BASE ensures that at least 40% of the texts identified are in open access, and cannot be guaranteed to the rest because of lack of metadata in the repositories. Through the oadoi.org service, you have access to over 5,000 repositories. However, BASE does not index the contents of these full texts. The search interface is quite advanced, possibly the friendliest of the whole family of plugins reviewed in this post. |
|
CORE claims to have about 70 million documents that, such as BASE, are retrieved through the OAI-PMH protocol. For this reason, they also have the same problem of linking the complete texts with certainty due to the lack of normalization of the metadata in the institutional repositories, in particular the "Green OA" (see note at the end of the table). On the other hand, CORE indexes the content of these complete texts. |
|
It is available in beta version, indexes about 100 million documents. It is a simple version, for the time being limited to searching only by the author’s name. Delivers results quickly indicating which of them are available in open access. |
|
Launched in 2014, it is a plugin that, so far, only works on Google Chrome. It is the most complex extension (something complicated too) and, among several services, it can check whether your institution has subscription services to the full text, present several citation metrics, get comments from systems like PubMed Commons, offers functions that allow you to create citations, and retrieve documents related to your query that may be of interest, also in open access. |
|
|
Owned by OCLC, it is a collective catalog that claims to have more than 50 million records of open access resources from OAI-PMH collection of more than 2,000 sources contributing to the catalog. Records are also available in the WorldCat interface. It has the same limitations as those indicated for BASE, CORE and collections based on the OAI-PMH protocol, limitations that are explained at the end of this table. |
|
It is a plugin created in 2013 by two students and must be installed in a browser that it is not Internet Explorer, but it is easily installed in Google Chrome. It has a few thousand registered users. In my experiments, however, I did not have much success. |
|
|
Created in 2015, it is directly installed and is possibly the preferred option. See a separate example below in this post. |
|
|
It is the newest member of the family, and may be a second choice. See a separate example below in this post. |
Note on the limitations of “OAI-PMH harvester”
The Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) is a protocol developed to collect metadata descriptions of electronic records deposited in files so that the service can create query indexes. The implementation of OAI-PMH requires metadata to follow the Dublin Core standard. Indexing engines and service aggregators based on the OAI-PMH protocol have difficulties with coverage of institutional repositories due to the fact that these repositories are very heterogeneous and use a large diversity of file management systems. Moreover, because it lacks clear metadata standards, it is not simple for indexing robots to determine whether or not the records distinguish the free full texts. This problem adds to the difficulties of indexing records based on Dublin Core metadata, as I described earlier in this blog3 about indexing repositories by Google Scholar.
Complementing the comments of the mentioned article1, to understand better, we must say that in the history of open access repositories, the OAI-PMH protocol was established to recompile only the metadata and in the complete texts. The reason behind this protocol was that it was assumed that most (if not all) of the repositories would offer the open access texts (such as the ArXiv model), and for this reason, in the OAI-PMH protocol there is currently no field to indicate whether the full text is open access or not.
The problem then arises when indexing the thousands of institutional repositories due to the fact that the role they play for these institutions goes beyond simply filing full documents in open access. Among other purposes is to support scholars’ “self-archiving”, to preserve a record of university activities, and to demonstrate the relevance of their scientific, economic, and social activities to increase their visibility and status. For these reasons, as Aaron Tay says, institutional repositories may contain no more than one-third of their full-text documents accessible. Because of these limitations, open access document aggregators ignore these problems, and index the repositories in their entirety, giving the mistaken idea that everything is available in free access to the full text.
To run the tests, I installed the applications on my Google Chrome version, and the buttons appeared on the browser toolbar as shown in the figure below:
(1) Lazy Scholar; (2) Google Scholar button; (3) Open Access button; (4) Unpaywall button;

Google Scholar button
It is a plugin released in 2015 that can be installed simply and directly. How does it work? Let’s say you’re on a page that you did not access through Google Scholar, and you want to know if there’s a free-access version of this document. What you should do, then, is to mark the title of the article with the mouse and click on the icon in the toolbar (Number 2 in the Toolbar figure above). Google Scholar will search in the background and open in a secondary window on the right displaying all the free access versions that are indexed:
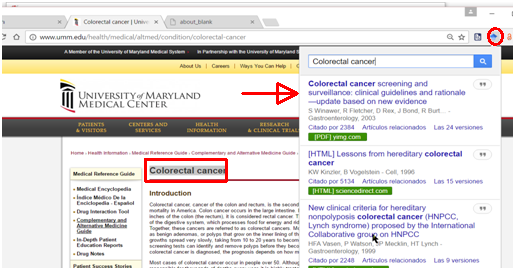
Unpaywall button
Once the extension is installed, when it reaches a page of any document, the icon of a padlock, which may be in different colors, will appear in the right margin of your screen, which has the following meanings:
- Green: the full text is in an institutional repository or preprint server
- Gold: this is from a journal article that has an open access license
- Blue: this is from a journal that does not have an open access license
- Black: no other versions were found in your index.
In the following example, the padlock on the right indicates that there is an accessible version, and clicking the icon will bring up the required text that has the URL shown below the figure::
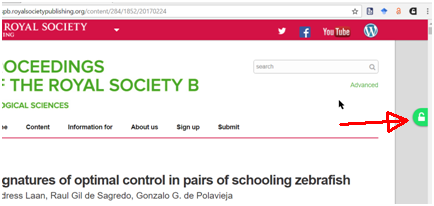
URL: http://rspb.royalsocietypublishing.org/content/royprsb/284/1852/20170224.full.pdf
Are these tools really effective in finding open texts?
In terms of efficiency, these tools can be categorized into two levels:
- In the first level are those that are based on direct search by Google Scholar, such as Lazy Scholar button, Google Scholar button and Unpaywall button.
- In the second level would be categorized all the other tools analyzed in this note.
The reason is that Google Scholar is the largest index of academic material available, despite having limitations when indexing repositories. All other initiatives, for the moment, are much smaller in terms of coverage, including aggregators such as BASE and CORE for the reasons explained above. On the other hand, Google Scholar has developed very efficient algorithms that allow to distinguish the different manifestations of the same article (preprints, versions, postprints, etc.)
Moreover, Google Scholar not only indexes repositories, but also all kinds of sites, including university Web pages. These documents are invisible to most of the analyzed plugins, which are mostly restricted to repositories, while Google Scholar indexes all documents that appear to be academic included in sites with an .edu extension.
It should also be noted that Open Access button services and those using Oadoi.org and similar ones do not index articles available at ResearchGate or Academia.edu due to the strong suspicion that many of these documents deposited by the authors violate the journals’ copyrights agreements, but are indexed by Google Scholar. According to a recent Scientometrics article4, it is estimated that about 40% of PDFs filed in ResearchGate violate copyright agreements.
My opinion
The amount of free-access full-text documents that can be retrieved with these tools has as its upper limit the total indexed by Google Scholar and as the lower limit the “legal” access documents recovered with OAIster and OA button, etc.
Unfortunately, due to the extensive distribution of documents in thousands of different places, and to the lack of consistency of standards with which data aggregators work, no method is 100% reliable nor consistent to find all open access full texts.
Since these tools are very new, only two or three years of development, my decision is that Google Scholar button and Unpaywall button are the most effective.
This opinion is temporary, and it is valid until my favorite nerd suggests me something else.
Notes
1. TAY. A. 5 services to help researchers find free full text instantly & a quick assessment of effectiveness [online]. Musings about librarianship, 2017. [viewed 03 May 2017]. Available from: http://musingsaboutlibrarianship.blogspot.com/2017/03/5-services-to-help-researchers-find.html
2. TAY. A. The open access aggregators challenge — how well do they identify free full text? [online] Musings about librarianship, 2017. [viewed 03 May 2017]. Available from: http://musingsaboutlibrarianship.blogspot.com/2017/01/the-open-access-aggregators.html
3. SPINAK, E. Latin-American repositories have little visibility in Google Scholar [online]. SciELO in Perspective, 2014 [viewed 15 April 2017]. Available from: http://blog.scielo.org/en/2014/09/18/latin-american-repositories-have-little-visibility-in-google-scholar/
4. JAMALI, H.R. Copyright compliance and infringement in ResearchGate full-text journal articles. Scientometrics [online]. 2017, pp 1-14 [viewed 15 April 2017]. DOI: 10.1007/s11192-017-2291-4. Available from: http://link.springer.com/article/10.1007/s11192-017-2291-4
References
100 MillionenNachweise in BASE [online]. BASE Weblog, 2016. Available from: http://ekvv.uni-bielefeld.de/blog/base/entry/100_millionen_nachweise_in_base
JAMALI, H.R. Copyright compliance and infringement in ResearchGate full-text journal articles. Scientometrics [online]. 2017, pp 1-14 [viewed 15 April 2017]. DOI: 10.1007/s11192-017-2291-4. Available from: http://link.springer.com/article/10.1007/s11192-017-2291-4
Protocol for Metadata Harvesting [online]. Wikipedia. 2017 [viewed 03 May 2017]. Available from: http://en.wikipedia.org/wiki/Protocol_for_Metadata_Harvesting
SPINAK, E. Latin-American repositories have little visibility in Google Scholar [online]. SciELO in Perspective, 2014 [viewed 15 April 2017]. Available from: http://blog.scielo.org/en/2014/09/18/latin-american-repositories-have-little-visibility-in-google-scholar/
TAY. A. 5 services to help researchers find free full text instantly & a quick assessment of effectiveness [online]. Musings about librarianship, 2017. [viewed 03 May 2017]. Available from: http://musingsaboutlibrarianship.blogspot.com/2017/03/5-services-to-help-researchers-find.html
TAY. A. The open access aggregators challenge — how well do they identify free full text? [online] Musings about librarianship, 2017. [viewed 03 May 2017]. Available from: http://musingsaboutlibrarianship.blogspot.com/2017/01/the-open-access-aggregators.html
External links
BASE – <http://www.base-search.net/>
CORE – <http://core.ac.uk/about>
Dissemin – <http://dissem.in/>
Google Scholar button – <http://chrome.google.com/webstore/detail/google-scholar-button/ldipcbpaocekfooobnbcddclnhejkcpn?hl=en>
Lazy Scholar button – <http://www.lazyscholar.org/>
OAdoi – <http://oadoi.org/faq>
OAIster – <http://www.oclc.org/en/oaister.html>
Open Access button – <http://openaccessbutton.org/>
Unpaywall – <http://unpaywall.org/>
 About Ernesto Spinak
About Ernesto Spinak

Collaborator on the SciELO program, a Systems Engineer with a Bachelor’s degree in Library Science, and a Diploma of Advanced Studies from the Universitat Oberta de Catalunya (Barcelona, Spain) and a Master’s in “Sociedad de la Información” (Information Society) from the same university. Currently has a consulting company that provides services in information projects to 14 government institutions and universities in Uruguay.
Translated from the original in Spanish by Lilian Nassi-Calò.
Related Posts:





Como citar este post [ISO 690/2010]:







You may also be interested in http://www.jurn.org/ which has been under active development since 2009. See also JURN’s journal directories at http://www.jurn.org/directory/ and https://jurnsearch.wordpress.com/titles-indexed-ecology-related/
Thanks Ernesto for naming me as your “favourite nerd”.
Since I wrote the post there’s a new commercial one on the scene, canaryhaz. This one handles both finding OA items as well as items within your institutional subscriptions and also helps store the PDF downloaded in the cloud.
It’s pretty new, and I have very little experience on it or hope it works.
Dear Aaron
Thanks for your comments, and please, keep writing in your blog!!!
Ernesto
Hi, developer of oaDOI and Unpaywal here. Nice article!
A clarification: Unpaywall (like the Open Access Button) uses oaDOI in the background. In fact, we built Unpaywall as a demo of the open oaDOI API (which in turn relies heavily on the BASE index). If and only if Unpaywall doesn’t find an open resource using oaDOI, then it checks Google Scholar.
If users don’t want to see Google Scholar results, they can turn the Google Scholar search off; you just go to preferences and tick the “hide content from less trusted sources” option.
Dear Jason
Thnks for the clarification,
Ernesto Spinak